Convert CSV and JSON to optimized analytics-ready Parquet.
Fast. Simple. Scalable. From small files to very large datasets.
A Purpose-built, lightweight but powerfull tool that runs inside your cloud or data environment, without ETL pipelines.
* We also offer private AMI deals via direct contract.
Delivery methods:
- Amazon Machine Image (AMI).
- CloudFormation Template (CFT).
Are your datasets getting expensive to store and query?
Storage costs keep growing.
Query costs increase with scanned bytes.
Transfers and reads take longer.
Are CSV and JSON slowing down analytics?
Queries take longer as data grows.
Text formats force engines to read and parse more data.
Costs rise with scanned bytes.
In query engines that support it, Parquet enables predicate pushdown and column pruning, which can significantly reduce scanned data and improve query performance.
Is Schema handling slowing you down?
CSV and JSON structures can drift over time.
Manual schema maintenance is brittle.
Mismatched fields can break downstream jobs.
Are ETL tools overkill for simple format conversion?
Complex pipelines for a straightforward task.
Operational overhead you may not need.
Longer setup and maintenance cycles.

Why Parquet Format?
The Gold Standard for Modern Data Architecture
In the world of Big Data, how you store your information is just as important as the information itself. Parquet is an open-source, columnar storage format designed for maximum efficiency, lightning-fast queries, and seamless scalability.
Performance Meets Efficiency
Traditional formats like CSV and JSON are row-based, forcing engines to read entire files just to access a single column. Parquet flips the script.
- Columnar Storage: Only read the data you need. By organizing data by column rather than row, Parquet drastically reduces the amount of data scanned during queries.
- Massive Storage Savings: Advanced encoding and compression techniques (like Snappy or Gzip) allow Parquet to occupy significantly less disk space than text-based formats.
- Reduced I/O Operations: Lower data volume means fewer "reads" from your storage layer, resulting in faster performance and lower cloud infrastructure costs.
How Parqify Works
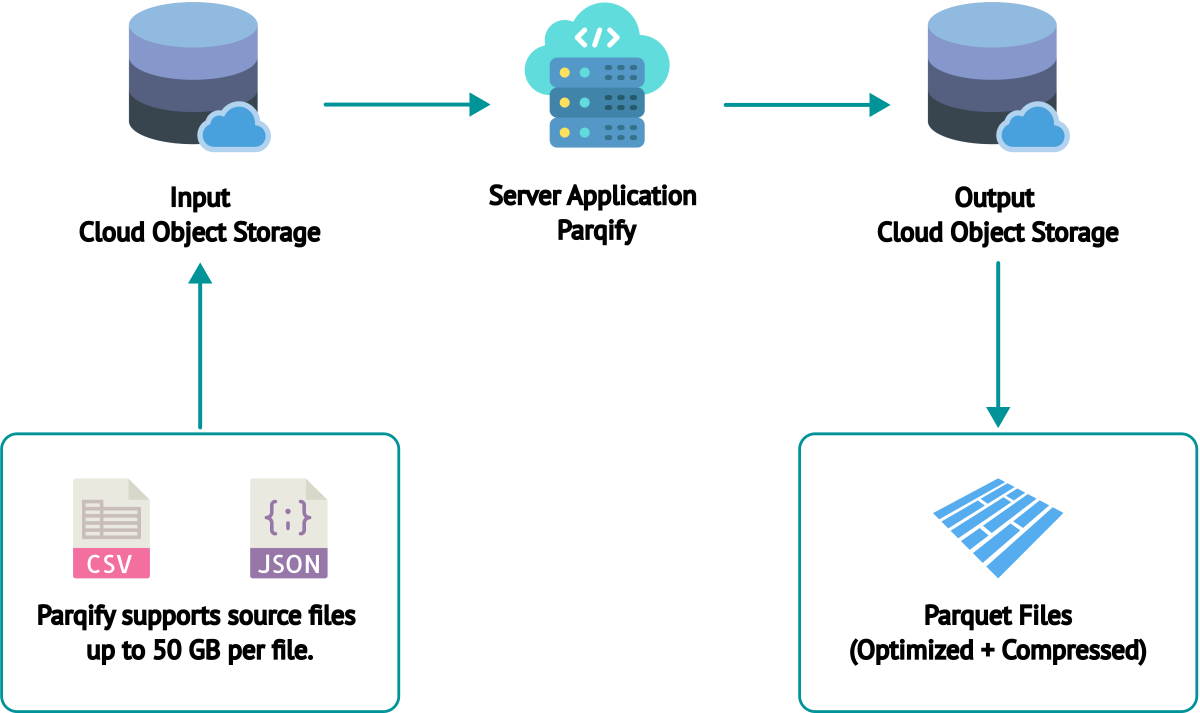
Parqify provides a server application, packaged as an AMI, that customers can deploy within their cloud environment.
This server reads CSV and JSON files from a specified cloud object storage, converts them to the Parquet format, and then writes the converted files back to a destination storage location.
🚀 High-Performance Architecture
Parqify is engineered to be the fastest bridge between raw data and Parquet.
Parqify is designed to utilize as much of the EC2 instance's capacity as possible to minimize conversion time.
Parqify process large datasets efficiently by converting multiple files concurrently.
Built with Rust
At the core of Parqify is a processing engine written entirely in Rust. This choice allows us to provide a level of performance that high-level languages simply cannot match:- Predictable Performance: No garbage collection pauses, ensuring consistent throughput even for massive datasets.
- Memory Safety: Rust’s strict safety guarantees eliminate common data corruption bugs at the compile level.
- Zero-Overhead: Our engine runs directly on the hardware, ensuring every cycle is dedicated to your data conversion.
Maximum Instance Utilization
Parqify is designed to utilize as much of the instance's capacity (such as an EC2 instance) as possible to minimize conversion time.
We don't believe in idle resources.
Speed is Savings. By maximizing instance capacity and leveraging Rust’s efficiency, Parqify reduces the compute time required for every job. You get your Parquet files faster, and your infrastructure works harder for you.
⚙️ Optimized for Conversion — Not General ETL
Parqify uses a lightweight streaming pipeline designed specifically for cloud object storage → Parquet conversion.
Unlike Spark-based tools, it avoids cluster startup, staging datasets, and JVM overhead. Files are streamed directly from cloud object storage into Parquet writers with column-aware buffering and parallel IO.
The results:
- 🚀 Faster startup
- 🚀 Lower memory usage
- 🚀 Fewer storage operations
- 🚀 Smaller Parquet output
- 🚀 Better performance for cloud analytics engines and data warehouses
Perfect for anyone who just needs Parquet — without building ETL infrastructure.
Ready to get started?
Launch on AWS Marketplace🎯 Precision Schema Control
Smart Inference & Easy Customization
Parqify automates schema inference and enforcement.
- Flexible Inference Modes: Choose how your schema is inferred—per file, based on the Largest File, or via a User-Provided Sample.
- Simple Schema Customization in UI: Define, edit, and manage custom schemas directly through our Web UI.
- Reliable Consistent Output: Combine automated inference with manual overrides for 100% reliable Parquet conversion.
🙂 Friendly WEB UI
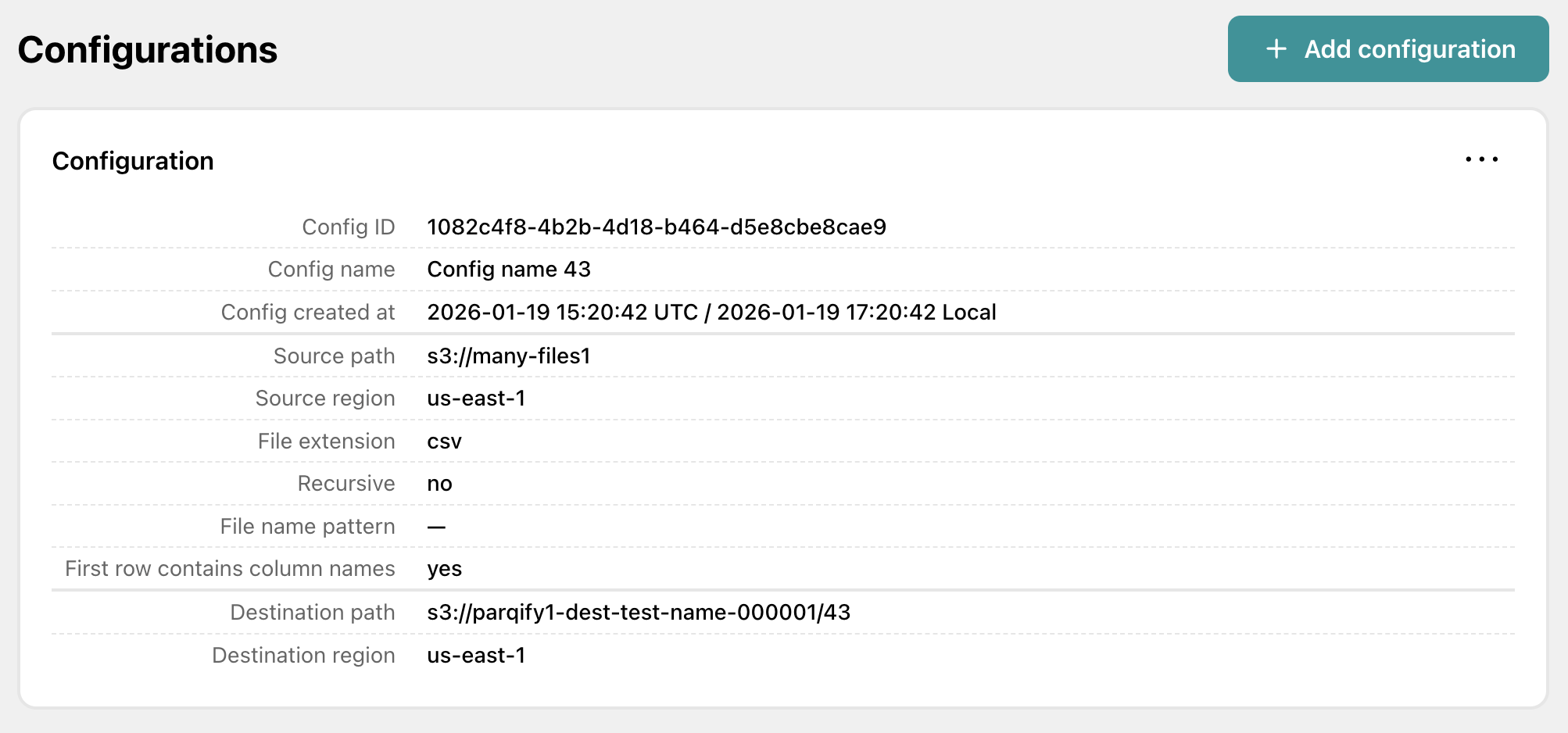
Create, edit, import/export conversion configs.
Configure S3 bucket names, file prefixes, and other conversion parameters through a simple web interface.